|
|
|
مقدمهدر مدلسازی معادلات ساختاری تصمیم گیری در مورد استفاده از PLS به جای تکنیک مدل سازی معادلات ساختاری مبتنی بر کوواریانس مانند LISREL برای مدل سازی علّی را می توان با نگاه کردن به تفاوت بین تحلیل مؤلفه های اصلی و تحلیل عاملی مشترک کمک کرد. از طریق چنین فرآیندی، این مقاله نیاز کاربران PLS را برای تغییر از پارامترهای مدل صرفاً تخمینی به مواردی که شامل معیارهای مربوط به پیش بینی است، بیان می کند. مگر اینکه اشتراک زیاد باشد و شاخصهای هر سازه بزرگ باشند، تخمینهای پارامتر PLS برای بارگذاری سازه احتمالاً دارای سوگیری همگنسازی و تخمین بیشازحد است. برعکس، مسیرهای ساختاری معمولا دست کم گرفته می شوند. محققان علاقه مند به یادگیری در مورد PLS در مدلسازی معادلات ساختاری باید یک بررسی کامل از تجزیه و تحلیل مؤلفه های اصلی، تجزیه و تحلیل مسیر، و رگرسیون OLS را تکمیل کنند. از استدلالهای مربوط به مزایا و معایب انتخاب یکی بر دیگری میتوان بهطور قیاسی برای مقایسه PLS با تکنیکهای مبتنی بر کوواریانس مانند LISREL استفاده کرد. در هر دو موقعیت، موضوعاتی که باید در نظر گرفته شوند عبارتند از رابطه معرفتی بین داده ها و نظریه (که شامل موضوع عدم تعیین عامل است)، عواملی که بر تخمین پارامترهای جمعیت (به عنوان مثال، حجم نمونه، جامعه، تعداد شاخص ها در هر عامل، و توزیع داده های نمونه) تأثیر می گذارند. به طور کلی، تفاوت اصلی بین تحلیل عاملی و تجزیه و تحلیل مؤلفه ها (بنابراین برای LISREL و PLS به همان اندازه صادق است) این است که آیا مایل به مدل سازی صریح واریانس عاملی منحصر به فرد برای متغیرهای آشکار است یا خیر. شاخصی که با متغیرهای پنهان در تحلیل مشترک نیست) و خطای اندازه گیری. همانطور که نسبت واریانس منحصر به فرد به دلیل واریانس خاص افزایش می یابد، تفاوت برای نتایج به دست آمده از یک روش مبتنی بر مولفه مانند PLS در تقابل با رویکرد تحلیل عاملی لیزرل بیشتر خواهد بود. این تمایز به صورت تحلیلی برای مدلهای دارای فاکتورهای متعامد (مانند مکآردل، 1990) و بهطور تجربی برای مدلهایی با عوامل مایل نشان داده شده است (ویدامن، 1993). مک آردل (1990) این تمایز را برای شکل دادن چندین گزاره متضاد تحلیل مؤلفه ها و تحلیل عاملی اتخاذ می کند. در قیاس، من پیشنهاد میکنم که این عبارات برای PLS و LISREL نیز در نظر گرفته شوند. نکته اول1) انتخاب روش بستگی به این دارد که آیا محقق می خواهد واریانس چند متغیره متغیرهای آشکار را به حداکثر برساند یا در بازتولید پارامترهای جمعیتی که زیربنای همه کوواریانس ها هستند؟ هدف PLS در درجه اول تخمین واریانس ساختارهای درون زا و به نوبه خود متغیرهای آشکار مربوطه آنها (اگر بازتابی باشد) است. تمرکز فقط از ارزیابی اهمیت تخمینهای پارامتر در مدلسازی معادلات ساختاری (یعنی بارگذاریها و مسیرهای ساختاری) به اعتبار پیشبینی منتقل شود. تکنیک استفاده مجدد از نمونه پیشبینیشده که توسط گیسر (1974) و استون (1975) توسعه یافته است، ترکیبی از اعتبار متقاطع و برازش تابع با این دیدگاه را نشان میدهد که «پیشبینی موارد مشاهدهپذیر یا مشاهدهپذیرهای بالقوه ارتباط بسیار بیشتری نسبت به تخمین سازههای اغلب مصنوعی دارد (گیسر، 1975، ص 320). ماژول فرعی PLSX برنامه Lohmöller’s PLS 1.8 این قابلیت را به عنوان بخشی از یک الگوریتم چشم بند ارائه می دهد (1981، ص 5.9-5.12). در چشم بند، بخشهایی از دادهها برای یک بلوک ساختاری خاص (یعنی شاخصها بر اساس موارد برای یک ساختار خاص) حذف میشوند و با استفاده از تخمینهای بهدستآمده از نقاط داده باقیمانده، اعتبار متقاطع میشوند. این روش با مجموعه متفاوتی از نقاط داده که توسط شماره حذف چشم بند دیکته می شود، تکرار می شود تا زمانی که همه مجموعه ها پردازش شوند. بنابراین یک اندازه گیری ارتباط حاصل برای ساختار درون زا مورد نظر به دست می آید. این معیار ارتباط عموماً آموزندهتر از R2 است و میانگین واریانس استخراجشده از آنجایی که دو مورد آخر دارای سوگیری ذاتی هستند که بر روی همان دادههایی که برای تخمین پارامترهای آن استفاده شدهاند ارزیابی میشوند. روشهای استفاده مجدد نمونه جایگزین با استفاده از bootstrapping یا jackknifing هنوز اجرا نشده است. نکته دوم2) LISREL از نظر ریاضی بر PLS برتری دارد. این نکته به این واقعیت اشاره دارد که LISREL یک مدل مبتنی بر جمعیت برای تخمین بارگذاری و برآورد مسیر ساختاری است. همانطور که BHT اشاره می کند، تنها تحت شرایط مشترک حجم نمونه بزرگ و تعداد زیادی شاخص در هر عامل، برآورد بارهای عامل و برآوردهای مسیر ساختاری به تخمین LISREL تقریب می زند. در غیر این صورت، بارگذاری ها در یک تحلیل PLS تمایل دارند بیش از حد برآورد شوند و مسیرهای ساختاری، برعکس، دست کم برآورد شوند (Dijkstra, 1983, p. 86). بررسی مولفه در مقابل تمایزات عامل مشترک همچنین نشان میدهد که اجتماع عامل دیگری است. برای مثال، مطالعه شبیهسازی ویدامن (1993) نشان میدهد که 3 تا 7 شاخص برای ارزیابی دقیق بارگذاری مؤلفهها برای عوامل متعامد تحت شرایط اشتراک بالا در جمعیت (یعنی بارگذاری 0.80 برای همه شاخصها) مورد نیاز است. اگر بارهای جمعیت زیربنایی در 60/0 اشباع کمتری داشته باشند، 10 تا 18 شاخص برای به دست آوردن یک ارزیابی دقیق مورد نیاز است. در غیر این صورت، بارهای تخمینی بیش از 10 درصد از مقادیر واقعی انحراف دارند (به عنوان مثال، بارگذاری واقعی 0.60 برابر با 0.757، بارگذاری 0.80 واقعی به عنوان 0.872 و بارگذاری 0.40 واقعی به عنوان 0.663 برآورد می شود). از سوی دیگر، تحلیل عاملی مشترک قادر به استخراج پارامترهای واقعی جمعیت است. با تمایل به تخمین بیش از حد بارها، برآوردهای مسیر سازه مربوطه برعکس دست کم گرفته می شود. شبیهسازی ویدامن (1993) نشان میدهد که در شرایط عامل مایل که همبستگی جمعیت بین عوامل 50/0 تعیین میشود، تجزیه و تحلیل مؤلفهها به تخمین 421/0 منجر میشود که الگوی بارگذاری برابر برای جمعیت در 80/0 تنظیم شود. زمانی که بارگذاری واقعی 0.40 باشد، برآورد به 0.182 کاهش می یابد. از سوی دیگر، تحلیل عاملی رایج، تمایل دارد که بارگذاری ها را کمی کمتر نشان دهد (یعنی 0.77 به جای 0.80 و 0.35 به جای 0.40) با نمایش بیش از حد مربوط به همبستگی در 0.537 تحت اشتراک بالا و 0.645 برای جامعه کم به همان اندازه مهم تمایل تجزیه و تحلیل مؤلفهها برای همگن کردن بارگذاریها برای یک سازه زمانی است که الگوی واقعی متفاوت است. اگر یک مدل عامل سه شاخص دارای بارهای جمعیتی 0.8، 0.6.، و 0.4 باشد، مطالعه Widaman نشان می دهد که تجزیه و تحلیل مبتنی بر مؤلفه با استفاده از چرخش عامل مورب به ترتیب به برآوردهای 0.771، 0.769 و 0.709 منجر می شود. در شرایط متعامد، برآوردها به ترتیب 825/0، 782/0 و 642/0 است. در نهایت، بارگیری اقلام تحت تجزیه و تحلیل اجزا می تواند بسته به باتری آزمایشی اقلام متفاوت باشد. ویدامن (1993) تجزیه و تحلیل دو مولفه را بر روی یک شاخص آزمایشی با بار جمعیتی مشخص 6/0 انجام داد. در تحلیل اول، دو آیتم دیگر با بارهای جمعیتی 0.80 تنظیم شدند. در تجزیه و تحلیل دوم، بارگذاری 0.40 بود. فراتر از برآورد بیش از حد مورد انتظار بارگیری جمعیت 0.60، برآورد بین دو شرایط متفاوت بود که به ترتیب منجر به 0.808 و .702 شد. بنابراین، تخمین بارگذاری آیتم از تجزیه و تحلیل مولفهها در باتریهای آزمایشی مختلف برای یک عامل مشترک ثابت نیست. از سوی دیگر، تجزیه و تحلیل عامل مشترک با استفاده از اجتماعات تکرار شده و چرخش متعامد، قادر به بازتولید مقادیر جمعیت بود. بنابراین، برتری LISREL نسبت به PLS به توانایی تخمین پارامترهای زیربنایی جمعیت اشاره دارد. همانطور که در بیانیه یک اشاره شد، اگر هدف به حساب آوردن واریانس چند متغیره به معنای پیش بینی کننده باشد، این موضوع کمتر نگران کننده می شود. علاوه بر این، در شرایط دانش نظری پایین که BHT پیشنهاد میکند برای بسیاری از مطالعات مبتنی بر فناوری صادق است، تخمین محافظهکارانهتر از مسیرهای ساختاری یک مدل ممکن است مناسبتر باشد. تخمینهای PLS برای مدلهای نادرست که در آن مسیرهای ساختاری غیر قابل توجهی پیشنهاد شدهاند، بهطور پیشفرض به اندازه تخمینهای LISREL معادل بزرگی نخواهد بود. نکته سوم3) LISREL از نظر آماری نسبت به PLS برتر است. این گفته نسبتاً بحث برانگیز است و به دیدگاه محقق بستگی دارد. عبارت معکوس نشان می دهد که PLS دارای ویژگی های نمونه گیری آماری بهتری نسبت به LISREL است، می تواند به همان اندازه انجام شود. BHT با توجه به این که PLS هیچ فرض توزیعی در مورد داده ها ندارد، موضع دوم را اتخاذ می کند. این بیانیه که PLS هیچ فرض توزیعی ندارد به بازده مجانبی تخمینگر OLS مربوط می شود. با این حال، به دلیل ماهیت الگوریتم PLS، تخمینهای امتیاز سازه مغرضانه هستند و تنها در شرایط اشتراک بالا، تعداد مناسب شاخصها در هر سازه، و افزایش حجم نمونه سازگار هستند. با این وجود، از آنجایی که PLS یک روش تخمین اطلاعات محدود است، حجم نمونه مناسب بسیار کوچکتر از اندازه مورد نیاز برای یک روش اطلاعات کامل مانند LISREL است. BHT همچنین توجه داشته باشد که PLS امتیازهای مؤلفه را ایجاد می کند در حالی که LISREL ذاتاً نامشخص است. با این حال، همانطور که در بیانیه 1 ذکر شد و در بیانیه 2 توضیح داده شد، ارزش داشتن امتیازات جزء PLS باید بیان شود. تحت هدف تخمین پارامتر، مشخص نیست که آیا وزنها و بارگذاریهای PLS (و بنابراین امتیازات PLS) به اندازه نمونههای بهدستآمده از LISREL قابل تعمیم هستند یا خیر. نکته چهارم4) PLS از نظر عملی LISREL برتر است. PLS از نظر محاسباتی کارآمدتر از LISREL است به همان معنا که تجزیه و تحلیل مؤلفه ها سریعتر از تحلیل عامل حداکثر احتمال است. BHT به وضوح این نکته را با ذکر این نکته بیان می کند که مدل های بزرگ متشکل از شاخص ها و عوامل بسیاری را می توان در عرض چند دقیقه تخمین زد. در مقابل، زمان تخمین لیزرل با افزایش تعداد اندیکاتورها به طور چشمگیری افزایش می یابد. به طور خلاصه، درک مسائل مربوط به انتخاب مؤلفه در مقابل تحلیل عاملی رایج میتواند مبنایی برای انتخاب PLS یا LISREL به عنوان یک تکنیک تحلیل فراهم کند. BHT به وضوح بیان کرد که هدف LISREL تخمین پارامترهای مدل علی است در حالی که PLS به حداکثر رساندن واریانس توضیح داده شده است. برای درک بیشتر این نکته، فقط باید به تمایزهای تحلیلی مؤلفه/عامل نگاه کرد. در هر دو مورد، انتخاب شاخص ها و مدل نظری همچنان یک شرط ضروری است. هنگام استفاده از PLS، دانش نظری پایین لزوماً به معنای ناتوانی محقق در تعریف سازهها یا شبکه نومولوژیکی که این سازهها در آن قرار دارند، نیست. در عوض، احتمالاً مرحلهای اکتشافی در مدلسازی معادلات ساختاری را به تصویر میکشد که در آن یک محقق در حال آزمایش یک مدل موقت با موارد جدید توسعهیافته است. اگر آیتمهای مقیاس جدید ایجاد شوند (احتمالاً با میانگین اشتراک 60/0)، به نظر میرسد که برای به دست آوردن یک برآورد دقیق از یک مجموعه بسیار بزرگتر از شاخصها در هر سازه (در سطح تقریباً 12 تا 16) وجود داشته باشد. مسیرهای ساختاری برای PLS، توانایی کمتری برای تفکیک نشانگرهای ضعیف در یک باتری آزمایشی برای یک ساختار خاص وجود دارد. با توجه به تعصب همگن سازی و تخمین بیش از حد، در پذیرش موارد با بارگذاری کمتر از 0.80 محتاط خواهم بود. در نهایت حتی اگر مدل فرد متشکل از سازههایی با سطوح بالای سازگاری درونی باشد، به منظور سازگاری با هدف علّی-پیشبینیکننده PLS، باید تمرکز بیشتری بر ارتباط پیشبینیکننده یک مدل شود. |
|
| واژگان کلیدی:
مدلسازی معادلات ساختاری، تحلیل عاملی تاییدی، تحلیل مسیر، لیزرل، اسمارت پی ال اس. |
|
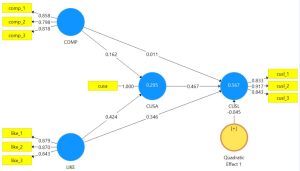
منبع:
Dijkstra, T. (1983). Some comments on maximum likelihood and partial least squares methods. Journal of Econometrics, 22, 67-90.
Geisser, S. (1974). A predictive approach to the random effect model. Biometrika, 61 (1), 101-107.
Geisser, S. (1975). The predictive sample reuse method with applications. Journal of the American Statistical Association, 70, 320-328.
McArdle, J. (1990). Principles versus principals of structural factor analyses. Multivariate Behavioral Research, 25 (1), 81-87.
Lohmöller, J. B. (1981). LVPLS 1.6 program manual: Latent variables path analysis with partial least-squares estimation. Munich: University of the Federal Armed Forces.
Stone, M. (1975). Cross-validatory choice and assessment of statistical predictions. Journal of the Royal Statistical Society, Series B, 36 (2), 111-133.
Velicer, W. F., & Jackson, D. N. (1990). Component analysis versus common factor analysis: Some issues in selecting an appropriate procedure. Multivariate Behavioral Research, 25 (1), 1-28.
Widaman, K. (1993). Common factor analysis versus principal component analysis: Differential bias in representing model parameters? Multivariate Behavioral Research, 28 (3), 263-311.