
در روش تحلیل پوششی داده ها،یک درک مشخص و واضح درباره واحدهای تصمیم گیرنده مختلف فراهم می آید و برخلاف روش های پارامتری که فقط بر روی پارامترهای جامعه توجه و تاکید می کند،به مشخصه ها و ویژگی های تمامی مشاهدات توجه می گردد.در روش های پارامتری باید یک معادله مشخص(معادله رگرسیون،تابع تولید و …)وجود داشته باشد که در قالب آن متغییر های مستقل و وابسته با یکدیگر ارتباط داشته باشند،در حالی که روش تحلیل پوششی داده ها، نیاز به هیچ گونه فرض یا فرم ریاضی خاصی نمی باشد.کارایی بدست آمده در روش تحلیل پوششی داده ها،کارایی نسبی است،و مرز کارایی توسط ترکیب محدبی از واحد های کارا ایجاد می شود.لذا هر واحد تصمیم گیرنده که بر روی مرز فوق قرار داشته باشد،کارا است و در غیر این صورت ناکارا خواهد بود.(شکل 1).
جهت کارا کردن یک واحد ناکارا باید تغییراتی در ورودی ها و خروجی های آن صورت گیرد.شایان ذکر است که پس از اجرای مدل های اساسی تحلیل پوششی داده ها،مجموعه ای تحت عنوان مجموعه مرجع ارائه می کردد.در این مجموعه مشخص می شود که هر واحد ناکارا برای رسیدن به مرز کارایی،باید با کدام یک از واحد های کارا مقایسه گردد. به عبارت دیگر در مجموعه مرجع برای هر یک از واحد های ناکارا، از میان واحد های کارا الگوهای قابل مقایسه ای(شامل یک یا تعدادی از واحد های کارا)فراهم می شود که از طریق آن واحد ناکارا می تواند خود را به مرز کارایی نسبی برساند.
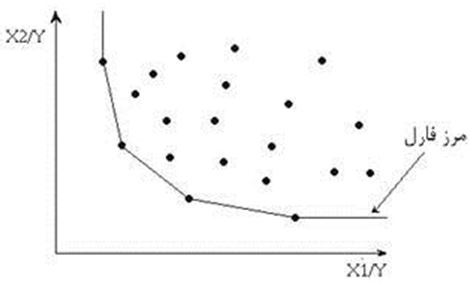
شکل (1) مرز کارایی
کارایی یک واحد سازمانی،حاصل نسبت ستاده به نهاده آن واحد می باشد.اگر یک واحد سازمانی بتواند با نهاده های کمتر،ستاده بیشتری را تولید کند،آن واحد سازمانی از کارایی بالاتری برخوردار خواهد بود.اگر واحدهای سازمانی، فقط دارای یک نهاده و یک ستاده باشند،کارایی حاصل ستاده به نهاده خواهد بود. اما اگر یک واحد سازمانی دارای نهاده ها و ستاده های مختلفی باشد،یافتن وزن مشترک برای ستاده ها و نهادهای مختلف مشکل و حتی غیر ممکن نیز می باشد.در اینجاست که باید از تحلیل پوششی داده ها استفاده کرد.